Future of App Tracking with SKAN 4.0’s Crowd Anonymity

Starting with SKAN 4.0
Most app marketers have faced difficulties with scaling & measuring their iOS app campaigns. The SKAdNetwork is designed to help us measure the success of ad campaigns, while we maintain maximum user privacy.
With Apple’s latest update to the SKAdNetwork, also referred to as SKAN 4.0 we have been introduced to a new notable feature, crowd anonymity. This article aims to shed light on this feature, its potential benefits, and how it could redefine the future of app tracking.
Disclaimer: By the time of writing this article (June, 2023) we are yet to experience the true impact of SKAN 4.0’s rollout in the ad networks.
What is crowd anonymity?
Crowd anonymity is a protective measure that enhances user privacy and determines the level of privacy assured to an app user based on the number of installs generated in a mobile user acquisition campaign.
The feature will simply withhold the attribution postback if the tracked installs are too low. This is designed to prevent any potential user identification, through rare data combinations.
On a high level, crowd anonymity is easy to understand in papers. If the number of app installs per campaign goes up, so does the level of crowd anonymity. As crowd anonymity goes up, Apple will enable more data capture for measuring campaigns, meaning that advertisers can get more data about campaign performance and can improve their ad strategies more quicker.
Opposite to this, when the crowd anonymity is low, the conversion value is masked. When crowd anonymity is medium, first postbacks include a coarse conversion value. And when crowd anonymity is high, first postbacks include a fine conversion value.
Digging deeper into crowd anonymity tiers
SKAN 4.0 introduces a method to handle privacy challenges by utilizing a four-tiered system of crowd anonymity, labeled 0, 1, 2, and 3.

Every install is assigned to one of these tiers by Apple, and this tier assignment determines the amount and specificity of data shared in the postback.
Note: Apple decides which crowd anonymity tier each install belongs to, and shares data accordingly.
These fields can include:
- The ‘source-identifier,’ is a hierarchical identifier that can comprise two, three, or four digits.
- The ‘conversion-value,’ a detailed conversion value, is only present in the first postback.
- The ‘coarse-conversion-value,’ a less detailed conversion value that the system sends in place of the ‘conversion-value’ in lower postback data tiers and in the second and third postbacks.
- The ‘source-app-id’ for ads displayed in apps, or ‘source-domain’ for attributable web ads.

This multi-tiered approach creates a nuanced privacy model, simultaneously protecting user information and providing marketers with varying degrees of actionable data.
Some would argue that it’s a nuanced way to balance the privacy concerns of users while offering marketers some level of insight into user behavior.
What does crowd anonymity mean for iOS marketers?
In an optimal situation: SKAN 4.0 will deliver a rich payload in the first postback, filled with fine-grained conversion values in the first postback and the second and third as coarse-grained values and an abundance of data at your disposal.

This implies a significant reduction in null postbacks, providing you with more extensive data to analyze and optimize your campaigns. In the table below, you can see how much data will be passed through each tier:
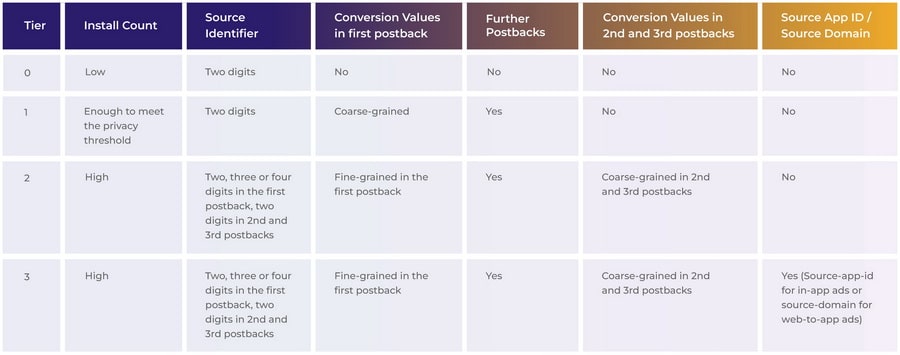
What you need to be aware of:
Reduced data granularity: Depending on the crowd size associated with an app or domain, you might receive less granular data in your postbacks. As you go down from Tier 3 to Tier 0, the amount of information in your postbacks decreases, with Tier 0 offering only the two-digit source identifier. This reduction in data granularity can affect the precision of campaign optimization and audience understanding.
So… is there really anything to be concerned about?
I believe it is important to note that the system calculates the tier based on various factors like crowd size, advertised app and hierarchical source identifier, selecting the identifier with the highest tier.
However, in scenarios where multiple identifiers share the highest postback data tier, the system opts for the one with the most digits. And for Tier 0 and Tier 1, it always selects the two-digit source identifier.
This seems to be a trade-off for ease and simplicity, but at what cost? This approach could potentially lead to the loss of valuable data or nuances that the extra digits would have provided, creating an oversimplified picture of the customer journey.
Losing important fields
Moreover, each tier affects the type of data you receive in your postback. In Tier 3, for instance, you get a fairly comprehensive set of data. But as you move down to lower tiers, you start losing important fields like ‘fine-grained conversion-value’, ‘second and third postbacks’ or ‘source-app-id/source-domain.’
By the time you hit Tier 0, you’re left with only the two-digit ‘source-identifier,’ a far cry from the granular insights that we marketers would strive to achieve.
Furthermore, the randomness introduced in the postback data tier selection and the limitations in data received based on these tiers introduce an element of uncertainty and complexity for marketers.

This could hinder the precision of data-driven decision-making processes that rely on consistency and predictability. All in all, while the intent behind the implementation of crowd anonymity is undoubtedly well-intentioned, it does present a slew of challenges and controversies.
An important thing to remember
It’s crucial to underscore that Apple has not laid out explicit criteria for meeting privacy thresholds or for classification into a specific tier.
Nevertheless, it is evident that concentrating more budget into a consolidated campaign setup can elevate crowd anonymity, thereby enriching the data yield.




